2020. 11. 1. 01:44ㆍComputer Science/Machine Learning💻
- Bias와 Variance의 차이는 무엇인가?
Bias란 데이터 내에 있는 모든 정보를 고려하지 않음으로 인해 지속적으로 잘못된 것들을 학습하는 경향을 의미한다.
Variance란 데이터 내에 있는 에러까지 모두 고려함으로 인해 실제 현상과 관련없는 것까지 학습하는 경향을 의미한다.
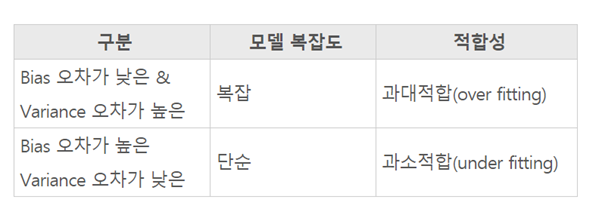
bias(편향)이 높다는 것은 실측치와 예측치간의 오차가 벌어진 것을 의미하며, Variance(분산)이 높다는 것은 예측의 범위가 높다는 것을 의미한다. 즉, bias가 높다는 것은 과소적합(underfitting, 꾸준히 틀리는 상황)이며 Variance가 높다는 것은 과대적합(Overfitting, 예측의 분포가 큰 상황)임을 의미한다.
모델에 있어 데이터를 충분히 학습시키지 않을 경우 실제 데이터를 예측하지 못해 Bias가 커질 것이고, 데이터를 과다하게 학습시킬 경우 노이즈까지 전부 학습하게 되어 Variance가 높아진다는 것을 의미한다.
따라서, bias와 variance는 trade-off관계이다.
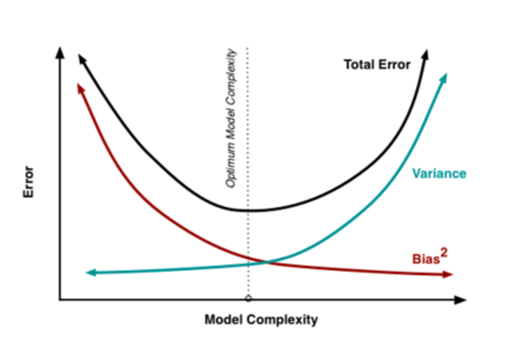
아래 그래프를 보면 쉽게 이해가 가능하다.
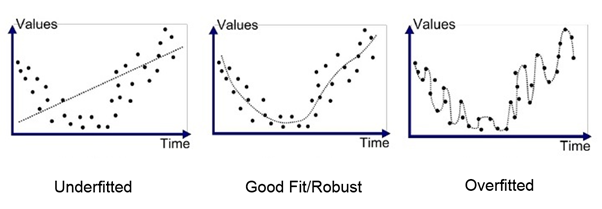
underfitting의 경우 데이터를 제대로 학습하지 못해 모델의 복잡도가 떨어지고(실제 데이터를 제대로 예측할 수 없는 상황), overfitting의 경우 데이터를 과다하게 학습해 모델의 복잡도가 높아진 모습을 볼 수 있다.(test set이 아닌 타 데이터를 예측할 수 없는 상태)
- overfitting을 어떻게 피할 수 있는가?
cross validation 혹은 더 많은 데이터의 학습, feature 삭제, regularization, Data augmentation 등이 있다.
- cross validation이란?
고정된 test set을 가지고 모델의 성능을 확인하고 파라미터를 수정하는 과정을 거치다보면 모델이 test set에 과다적합되는 현상이 발생한다. 그렇기 때문에 cross-validation이 나타나게 되었다.
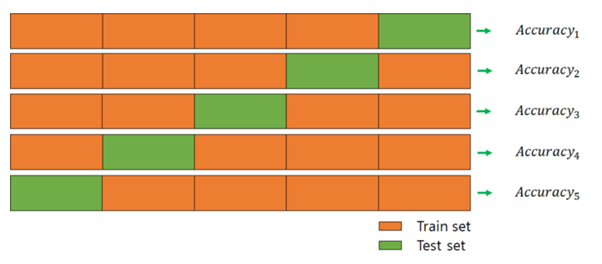
데이터 셋을 k개의 subset으로 나누어 각 subset내에서 test set과 training set으로 나눈 후 중복없이 바꾸어가며 평가를 진행한다. 모든 데이터 셋을 평가에 활용할 수 있으며, 데이터부족으로 인한 underfitting을 방지할 수 있다는 장점이 있다. 특히 K-Fold cross validation은 각 반복시 test set을 다르게 할당하여 K개의 데이터폴드 세트를 구성한다는 특징을 가지고 있다.
classification에는 stratified K-Fold cross validation이 있다.
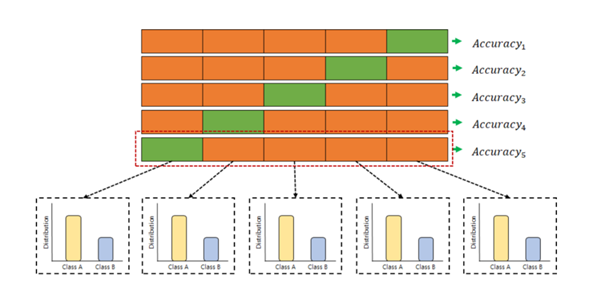
주로 분류문제에서 사용되며, label의 분포가 각 클래스별로 불균형을 이룰때 유용하게 사용된다.
이와 상반된 방법으로는 Hold out 방법이 있다.

holdout은 train과 test set의 비율을 9:1 혹은 7:3 비율로 나누어 쓰며, Iteration을 한번만 하기 때문에 계산 시간에 대한 부담이 적다는 장점이 있다. 반면에, 파라미터 튜닝을 반복하게 되면 모델이 test set에 대해 overfit될 가능성이 높다는 단점이 있다.
- 좋은 모델이란?
현재 데이터를 잘 설명하고, 미래 데이터에 대한 예측 성능이 좋은 모델이다.
현재 데이터를 잘 설명한다는 것은, training error를 minimize하는 모델을 의미한다.
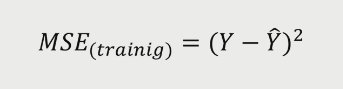

모델로써 조절할 수 있는 부분은 Bias와 Variance이며, 최대한 낮춰야 한다.
- regularization이란?
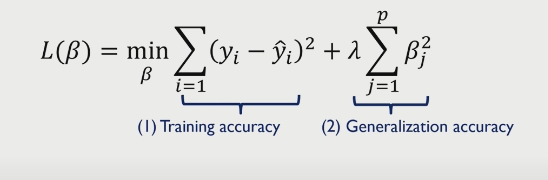
regularization(정규화)이란, 오차 함수에 특정한 패널티를 부여하는 기술이다. 정확히 말하면, 오차함수의 변동을 줄이기 위해(overfitting을 줄이기 위해) 특정 상관계수가 0이 되도록 제한하는 것이다.
MSE를 줄이기 위해서는 다음과 같은 공식이 있다. 앞부분은 Training data에 대한 정확도를 위한 것이며, 뒷부분은 정규화, 즉 test data에 대한 정확도를 위한 것이다. (lamda는 파라미터로 1과 2로 나뉜다)
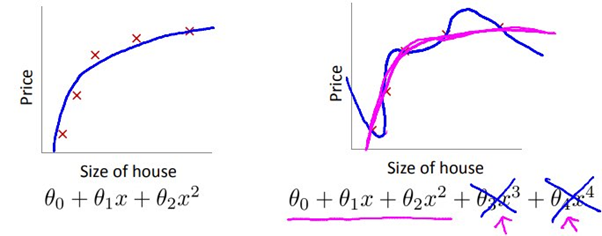
람다를 크게 하면, 모든 베타값이 0이 되며 직선 형태의 모델이 되며, underfitting된다.
lambda가 큰 경우, beta값이 극단적으로 작아지므로 constant한 모델이 생성된다(underfitting)
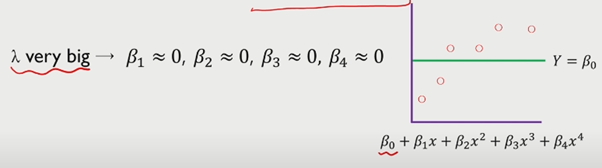
lambda가 작은 경우, beta에 대한 제약이 없어지므로 overfitting된 결과를 가지게 된다.
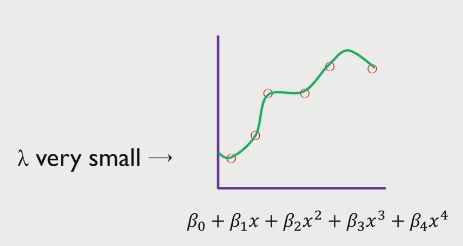
따라서, regularization은 회귀 계수 beta가 가질 수 있는 값에 제약조건을 부여하는 방법이며 MSE와 차이가 있다.
또한 제약 조건에 의해 bias가 증가할 수 있지만, variance는 감소한다는 특징이 있다.
제약을 걸지 않았을 때의 차트를 살펴보자.
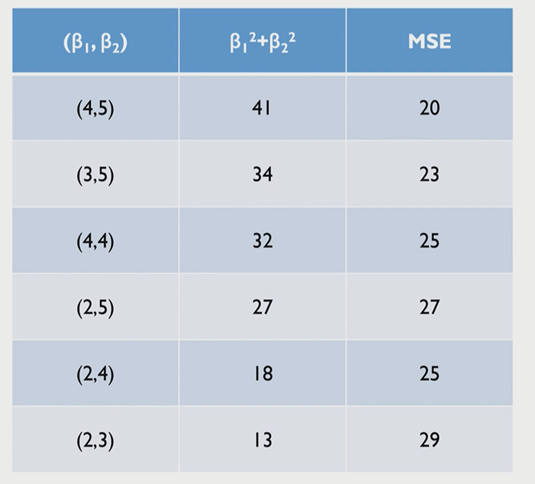
여기에서 가장 적합한 Beta는 MSE가 가장 작은 (4,5)가 될 것이다.
그러나 beta에 제약이 있는 경우는 아래와 같다.
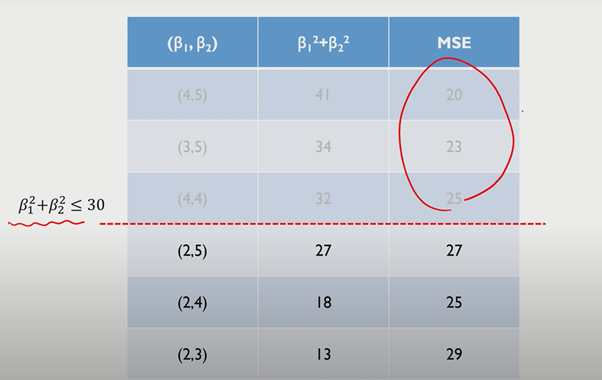
위 같은 차트에서는 (2,4)가 최상의 Beta가 될 것이다.
- Norm이란?
Norm은 벡터의 크기를 측정하는 방법으로, 두 벡터 사이의 거리를 측정하는 방법이다.
- L1/L2 regularization이란?
regularization(정규화)는 모델이 과도하게 학습하는 것을 통제하는 것이며, 상관계수(Beta)에 대한 패널티는 두가지로 나뉠 수 있다.
1) L1 regularization(Lasso regression) 과 2) L2 regularization(Ridget regression) 이다.
기존에 설명했듯이, regularization은 MSE를 최소화 하는 것이다. MSE를 최소화 하는 방법으로, 다음 예시를 통해 이해해보자.
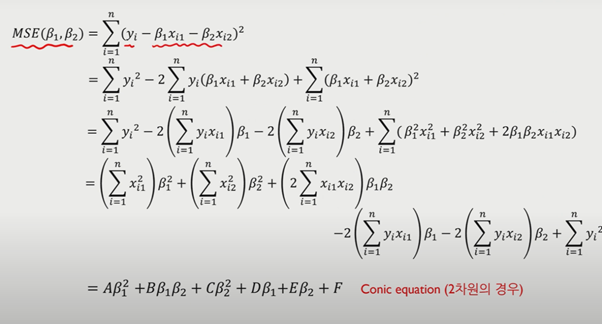
다음과 같이 X가 2개인 모델의 경우 MSE 공식을 풀면 다음과 같은 Conic equation을 얻을 수 있다.

또한 이러한 equation은 판별식에 따라 다음과 같은 그래프 형태를 얻을 수 있으며 MSE의 경우 타원에 해당한다.
다시 L2 regularization로 돌아와보자.
L2 Regularization의 경우 특정 beta에 대한 값에 제약을 주는 형태이다.
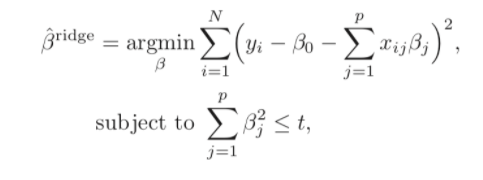
기존에 beta에 제약을 걸지 않았을 경우의 에러 최소와, 제약조건을 걸은 상태의 에러 최소가 서로 접점이 되기위해 계속해서 MSE를 키우고 제약조건을 만족하는 에러최소를 찾게 된다.(beta값의 크기 증가와 variance의 증가, Bias의 감소)
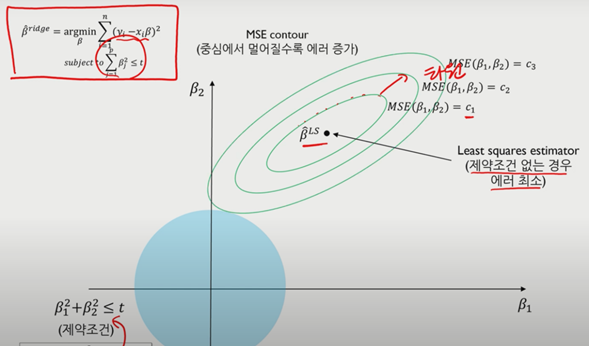
제약 조건을 가지게 되면 LSE(Least squares estimator)보다 작아지게 되며, 이를 shrinkage하다고 한다.
t가 커질수록 제약이 적어지며, t가 작아질수록 제약이 강해진다. t값이 큰 경우, 제약이 없는거나 다름 없으며 LSE가 포함이 된다.
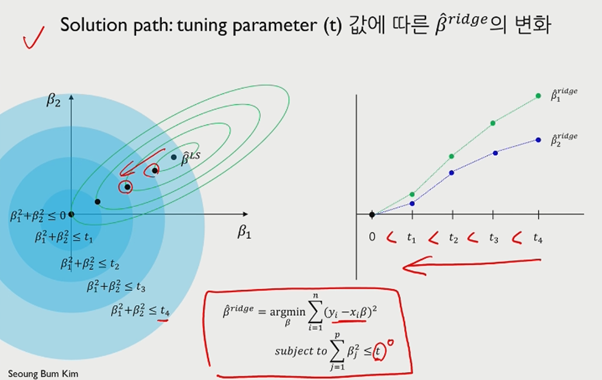
우측 그래프와 같이 t값이 클수록 beta가 작아진다고 볼 수 있다.
다음은 L1 Regression이다.
Lasso는 beta를 shrinkage할 뿐만 아니라 y에 있어 중요한 x 변수를 selection한다는 데에 있어서 차이점이 있다.
특히, ridge와는 다르게 절댓값을 이용하여 beta를 제약한다는 특징이 있다.

MSE의 공식을 사용하면 Lasso는 마름모 꼴로 표현이 되며, 꼭짓점과 같이 불연속적인 부분이 존재한다는 특징이 있다.
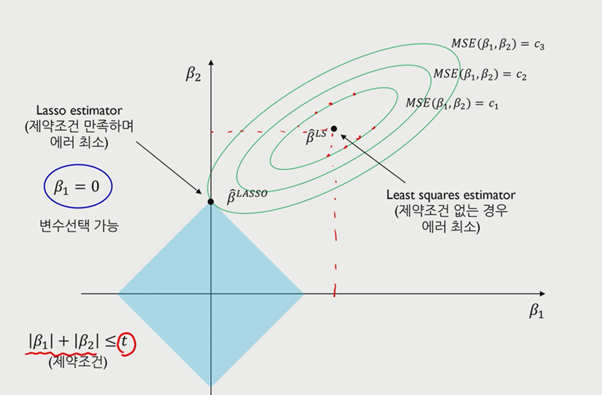
Beta가 0이 되는 경우, 결과값에 큰 영향을 미치지 못한다는 의미이므로 0이 되는 값을 제외한 나머지 beta를 선택하여 모델을 간소화한다. 절댓값이라는 특징 때문에 lasso는 미분이 불가능하다.

lamda가 매우 크게 되면 beta에 대한 제약이 커지므로 beta가 모두 0이 되는 상황이 일어나며 constant한 model이 생성된다.
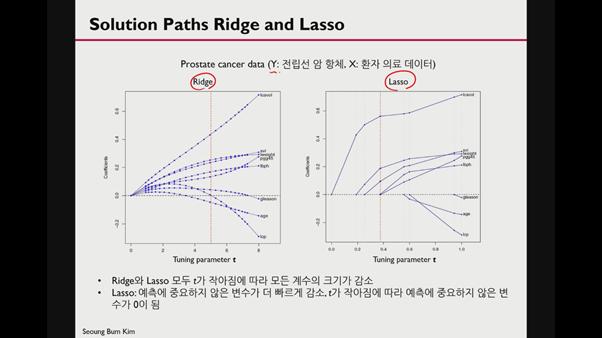
ridge는 parameter에 제약을 가하면 shrink한다. 반면 lasso의 경우 절댓값이란 특징으로 인해 0으로 떨어진다.
그래프를 통해 0이 아닌 변수의 경우 중요하며(output에 영향을 미치는 변수), 이들을 select해야 된다는 뜻이 된다.
ridge와 lasso의 경우 차이점은 다음과 같다.
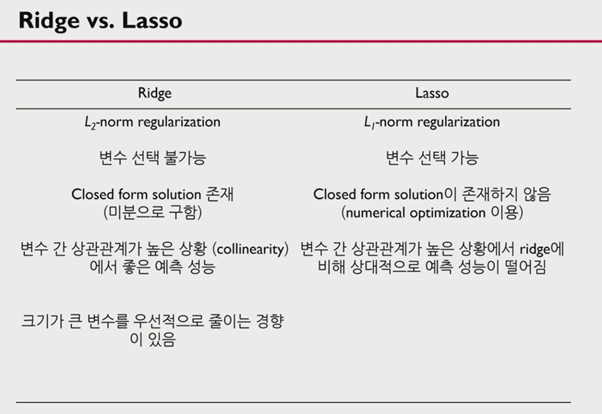
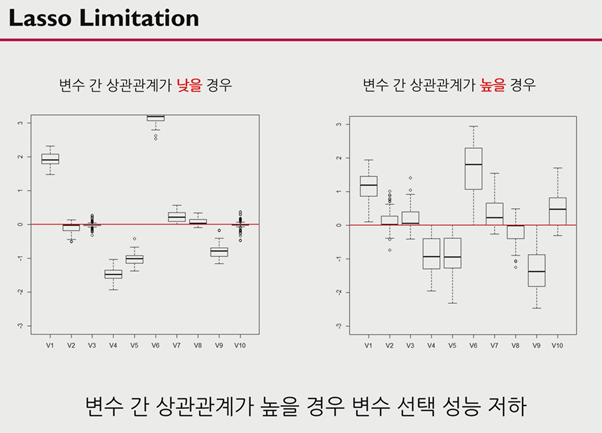
그러나 lasso의 경우 변수간 상관관계가 높을 경우 변수 선택에 있어 성능이 저하될 수 있다는 단점이 있다.
종합해보면 L1 과 L2는 다음과 같은 차이를 가지고 있다.
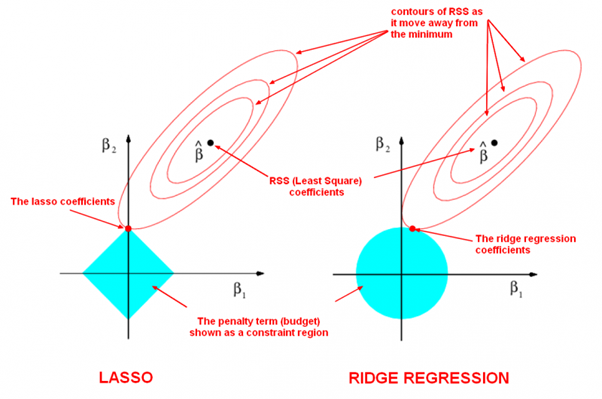
- lamda를 어떻게 설정할 것인가?
큰 값의 경우 적은 변수로 인해 간단한 모델이 생성되며, underfitting의 위험이 있다.
반면 작은 값의 경우 많은 변수가 생성되어 복잡한 모델이 생성되며, 해석이 어렵고 overfitting의 위험이 있다.
- Data augmenttion 이란?
Overfitting을 줄이기 위해 dataset을 증가시키는 방법 중 하나이다. 데이터를 충분히 수집할 수 없다면, 데이터를 왜곡시키거나 확대, 회전, 축소등으로 데이터를 증가시킨다.

- Accuracy란?
올바르게 예측된 데이터의 수(예측 결과와 실제 결과가 동일한 경우)를 전체 데이터의 수로 나눈 값이다.
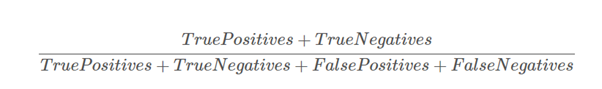
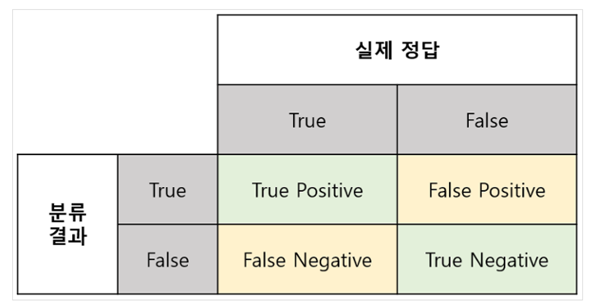
- Recall이란?(sensitivity, 정답의 입장)
실제로 true인 데이터를 모델이 true라고 인식한 데이터의 수.
accuracy는 시스템의 결과(출력)가 참값(true)에 얼마나 가까운지를 나타나고 precision은 시스템이 얼마나 일관된 값을 출력하는지를 나타낸다. 즉, accuracy는 시스템의 bias를, precision은 반복 정밀도를 나타낸다. 예를 들어, 몸무게를 재는 저울이 있는데 50kg인 사람을 여러 번 측정했을 때 60, 60.12, 59.99, ... 와 같이 60 근방의 값으로 측정했다면 이 저울의 accuracy는 매우 낮지만(에러가 10kg이나 발생함) precision은 매우 높다고 말할 수 있다.
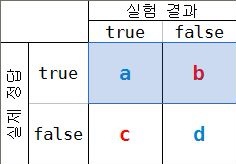
· precision이란?(모델의 입장)
모델이 ture로 예측한 데이터 중 실제로 ture인 데이터의 수.

· F1 score란?
F1 score는 precision과 recall의 조화 평균이다.

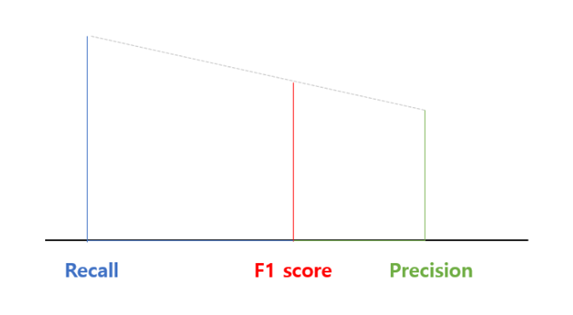
- SVM이란?(Support vector machine)
classification에 사용할 수 있는 머신러닝 지도 학습 모델. 분류를 위한 기준 선을 정의하는 모델이다.
2개의 속성만 존재하는 경우 다음과 같은 선의 형태를 지닌다.
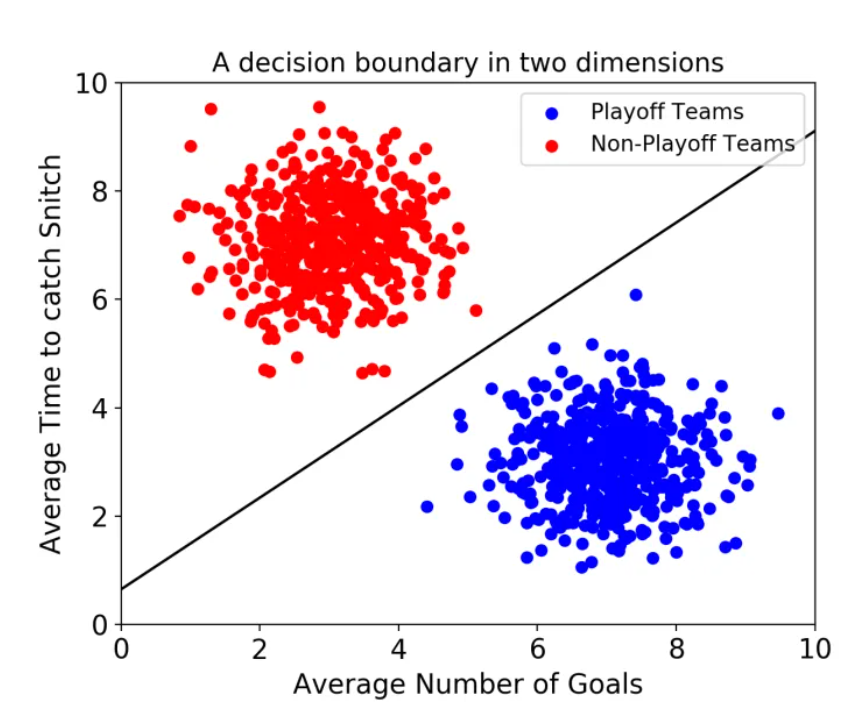
속성이 3개로 증가하는 경우, 다음과 같은 3차원 맵에 표현이 가능하다.
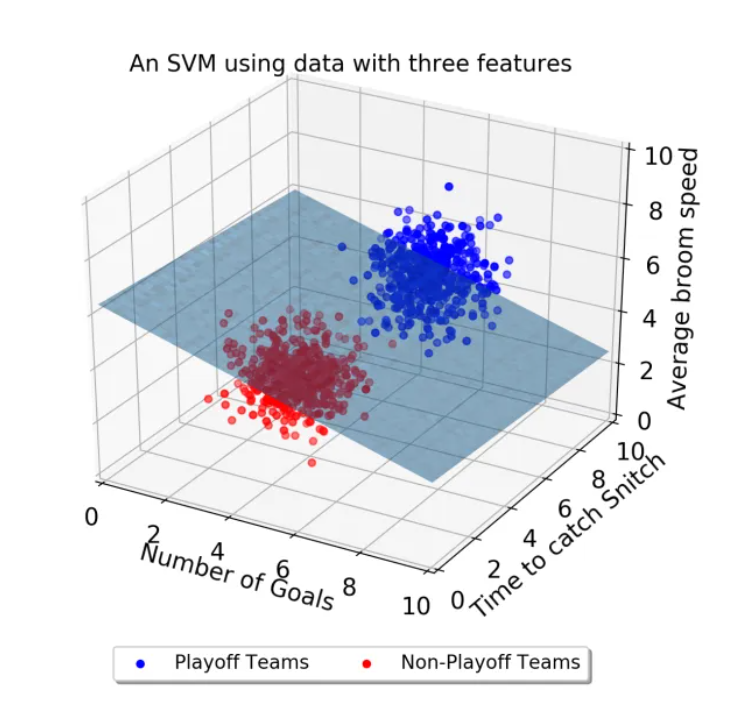
속성이 3개로 증가할 경우 결정 경계는 선이 아닌 평면이 된다. 또한 결정경계와 서포트 벡터 사이의 거리를 Margin이라 하며, 마진이 극대화 될수록 최적의 결정 경계라고 판단한다. 뿐만 아니라 SVM은 이상치를 얼마나 허용할 것이냐가 가장 중요한 안건이다.
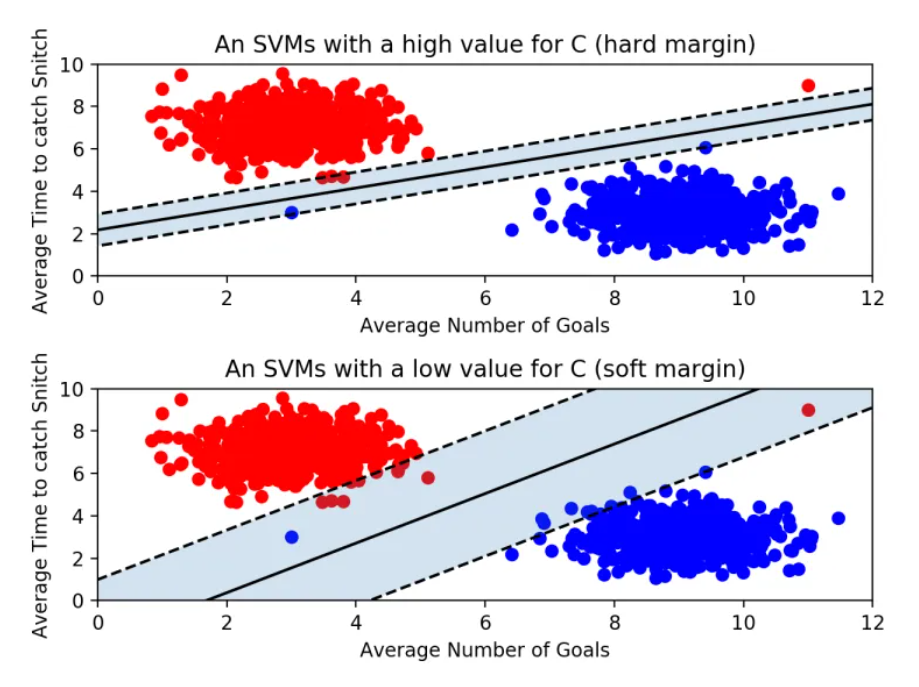
상단 그래프의 경우는 'Hard Margin'이라하며, 이상치(outlier)를 허용하지 않고 기준을 까다롭게 세운 경우이다. 이러한 경우 마진이 작아진다. 즉 개별적인 학습 데이터들을 모두 놓치지 않기 위해 이상치를 허용하지 않으면 overfitting의 우려가 있다.
반면 하단 그래프의 경우 'soft margin'이라 하며 이상치를 어느정도 수용하는 모델이다. 이러한 경우 마진이 커지지만 학습이 제대로 이루어지지않아(분류를 제대로 하지 못해) underfitting이 일어날 수 있다.
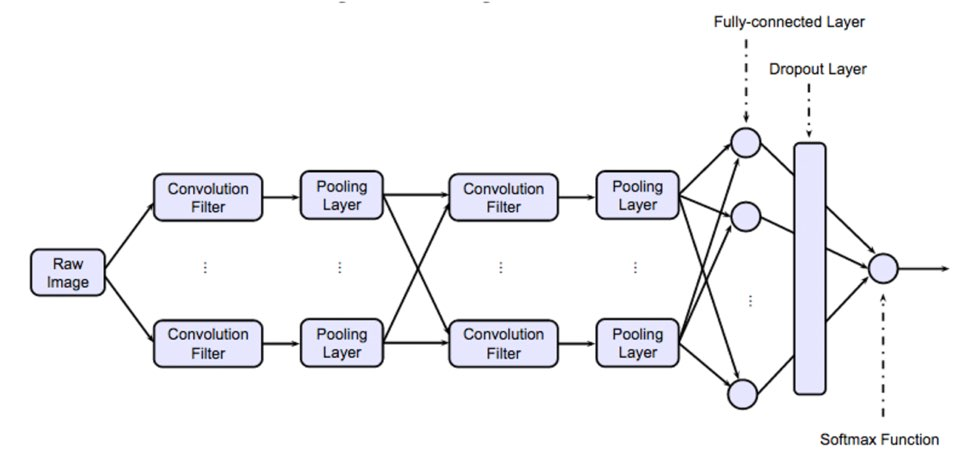
- CNN(Convolutional Neural Network)이란?
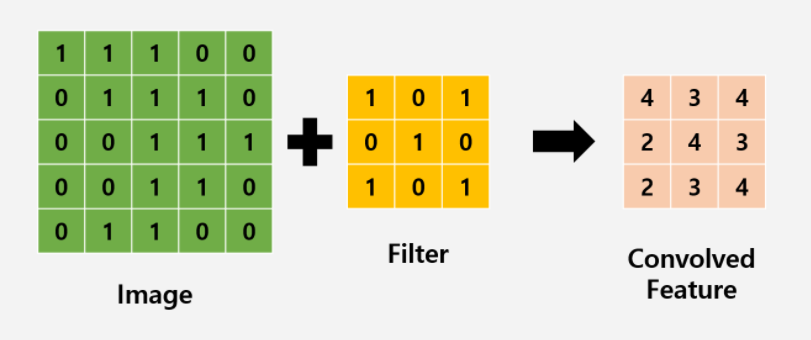
이미지를 인식하기위해 패턴을 찾기위한 뉴럴 네트워크이다. 특히 convolution이라는 단어가 중요한데, image전체를 보는 것이 아닌 특정 부분, filter에 초점을 맞추는 것이다.
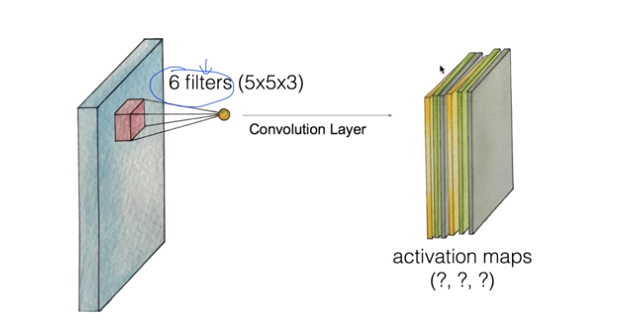
만약 image가 7x7 사이즈라고 가정한다면, 3x3의 filter를 적용할 경우 총 9개의 parameter가 존재하고, 이러한 parameter를 x라고 한다면 가중치 W에 대해 Wx+b와 같은 Actvation 함수를 거쳐 하나의 실수로 출력이 가능하다. 이때 filter를 옮기는 양을 stride라고 하며, 아래 GIF를 통해 예시의 경우 Stride가 1임을 알 수 있다.
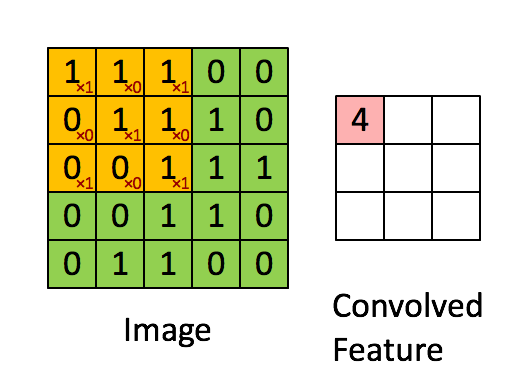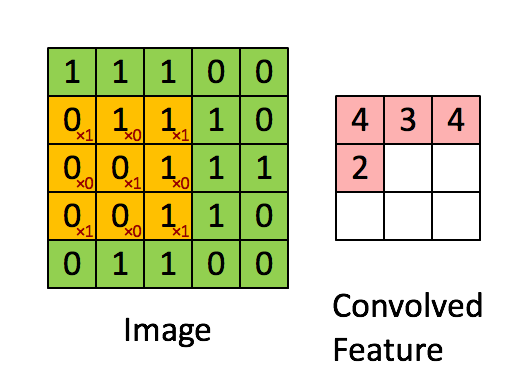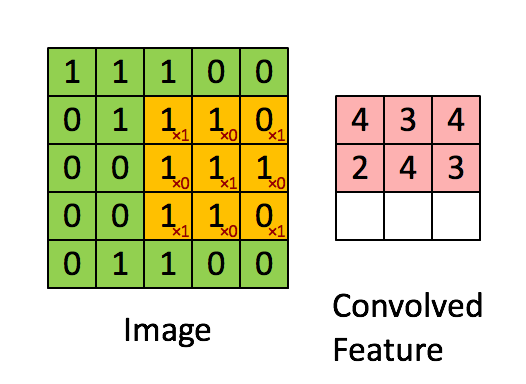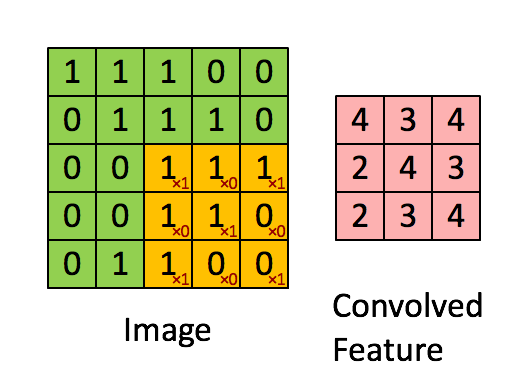
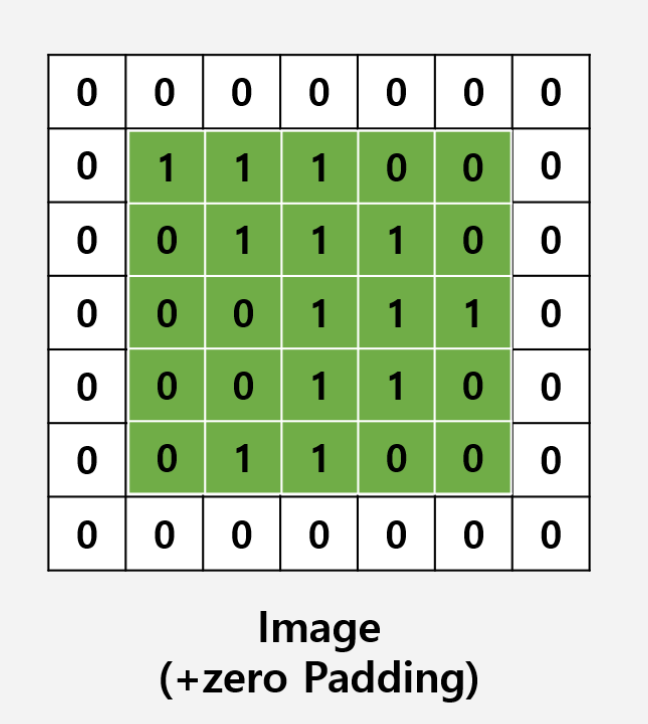
다음과 같은 filtering을 진행함으로써 얻게 되는 output을 convolution layer라고 부른다. 또한 이러한 convolution은 여러번 진행을 할 수 있다. 그러나 위의 과정을 통해 보이듯이, 5x5 사이즈의 image가 convolution을 거치면서 layer의 사이즈가 3x3 사이즈로 축소가 된다. 이러한 데이터 손실을 줄이기 위해서는 padding을 사용한다.
기존 이미지 크기에 맞춰 양옆에 0을 덧대 사이즈를 확장시킨다.
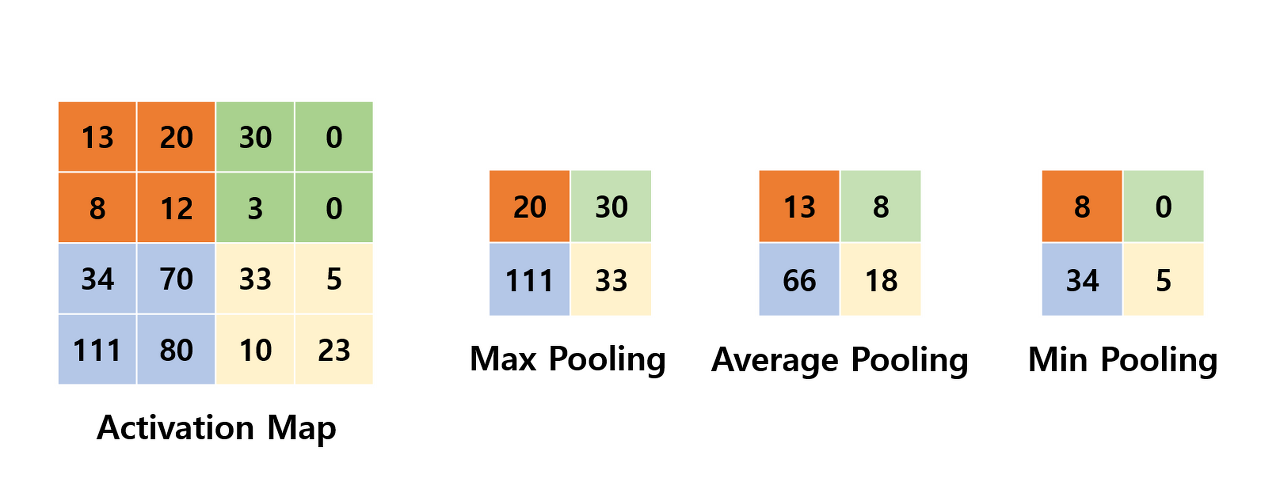
그러나 이러한 padding을 지속하다보면, 연산량이 기하급수적으로 늘기 때문에, 적당히 크기를 줄이고 특정 feature를 강조해야할 때, 그러한 역할을 Pooling layer에서 하게 된다.
Max Pooling/Average Pooling/Min Pooling이 있지만, CNN에서는 주로 Max Pooling을 사용한다.
이러한 구조를 종합하면, 다음과 같은 전체 구조를 이해할 수 있다.
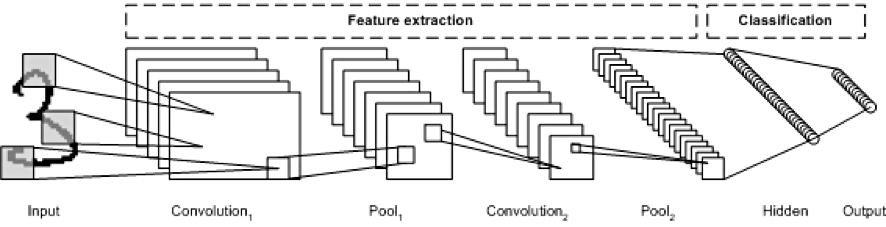
특징 추출 단계(Feature Extraction)
- convolution layer: 필터를 통해 이미지의 특징을 추출
- pooling layer: 특징을 강화하고 이미지의 크기를 줄임
이미지 분류 단계(Classification)
- Flatten Layer
- Softmax Layer(Classfication 수행)
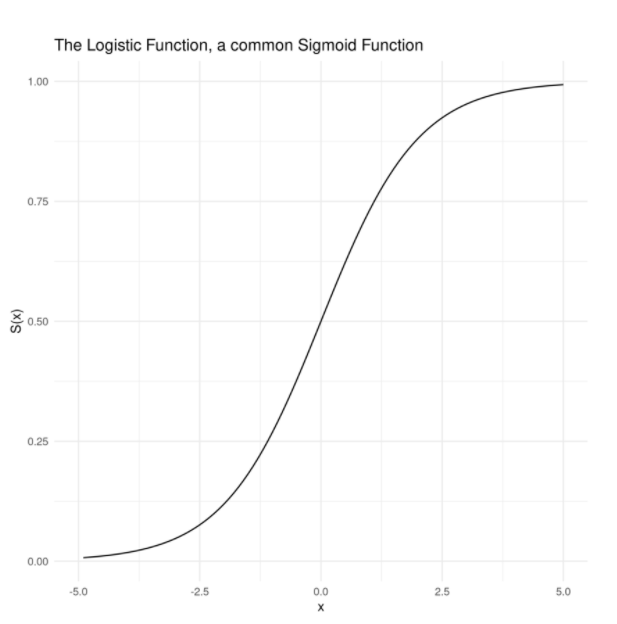
- sigmoid 함수란?
sigmoid 함수는 S-형태의 커브를 지닌 함수이다. 범위는 0 에서 1 혹은 -1에서 1로 이루어지며, 실수를 확률로 변환하는 역할을 한다. 일반적으로 로지스틱 회귀에서 사용된다.
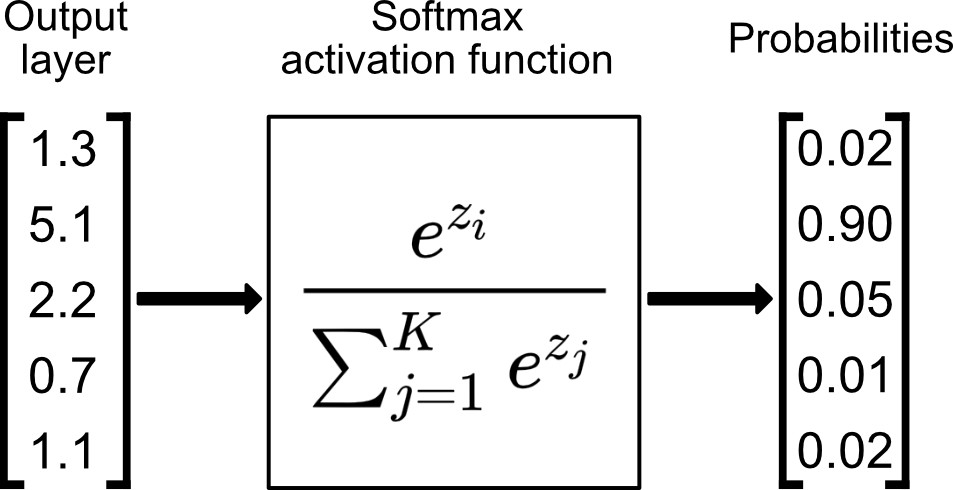
- Softmax 함수란?
모든 입력값(음/양수 와 0)에 대해 0과 1사이의 값으로 변환하는 함수이며, 확률로 해석할 수 있다.
만약 입력값이 극소하거나 음수라면 매우 작은 확률을 반환할 것이다. 일반적으로 다중 클래스 문제에서 사용된다.
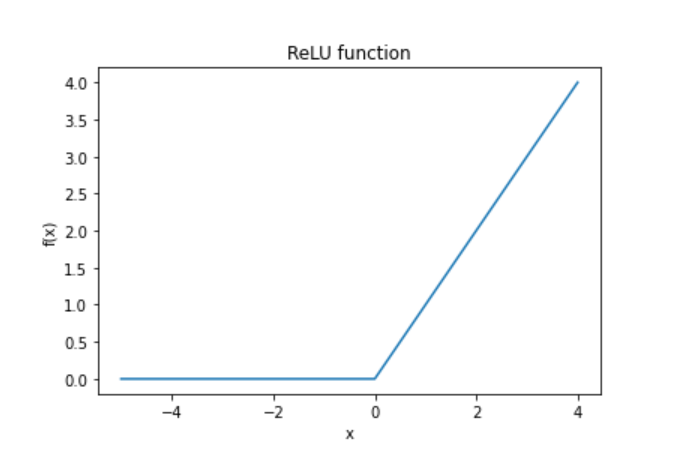
- ReLU 함수란?
기울기가 1로, nural networks에 있어 학습을 빠르게 할 수 있도록 도와주는 활성화 함수다.
음수에 대해서는 0을, 양수에 대해서는 입력값 그대로를 반환한다는 특징이 있다.
- Drop out이란?
정규화의 형태 중 하나로, 뉴럴 네트워크가 학습중일 때 랜덤하게 뉴런을 종료시켜 학습을 방해하여 학습이 training set에 치우치는 것을 예방한다.
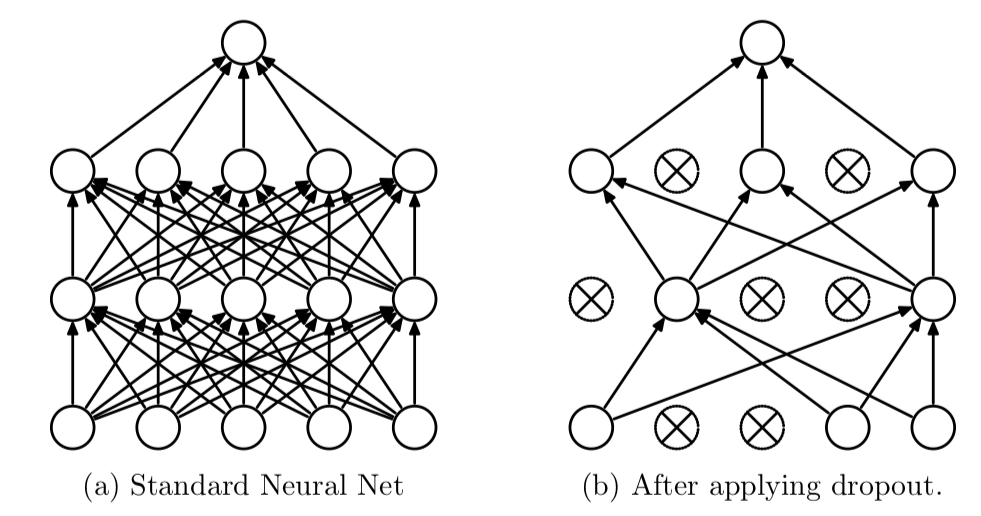
좌측은 일반적인 neural network이며, 우측이 drop out을 적용한 neural network이다.
- transfer learning이란?
규모가 큰 모델을 학습시킬 때 처음부터 새로 학습시키는 것은 속도가 느리다는 문제가 있다. 이러한 경우 기존에 학습된 DNN모델이 있을 때 이 모델의 하위층을 가져와 재사용하여 학습 속도를 빠르게 할 수 있을 뿐만 아니라 학습에 필요한 Training set이 훨씬 적다는 장점이 있다.
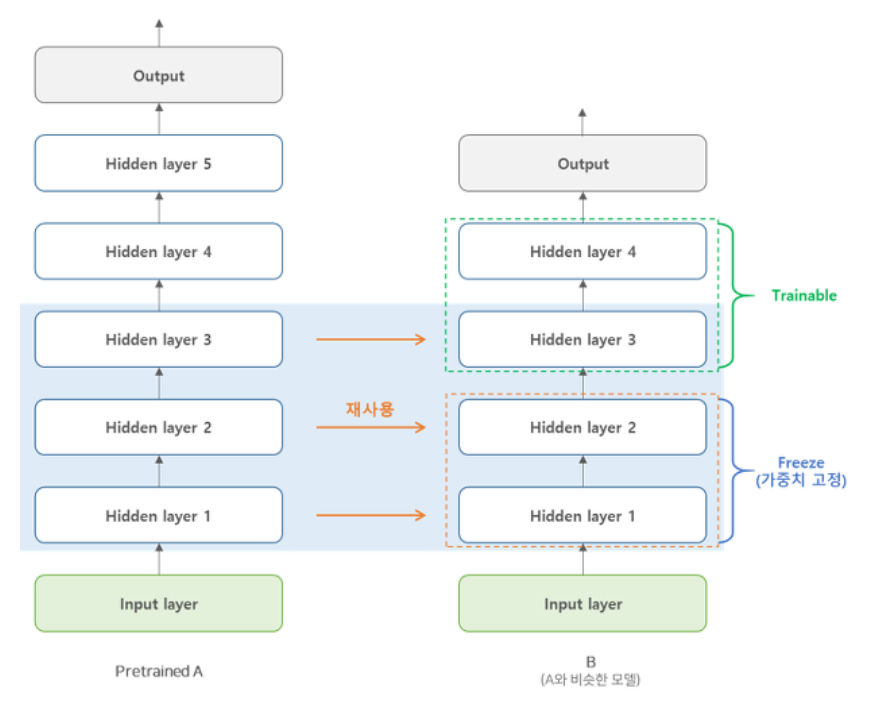
'Computer Science > Machine Learning💻' 카테고리의 다른 글
| [2] 추정과 가설 검정 (0) | 2020.11.08 |
|---|---|
| [1] 이산형/연속형 확률분포 (0) | 2020.11.05 |
| 데이터 사이언스 인터뷰(1) (0) | 2020.11.01 |
| easily image crawling with python and save in local drive (3) | 2020.03.06 |
| 머신러닝이란 무엇인가? (0) | 2020.03.03 |