2022. 10. 18. 16:17ㆍComputer Science/CS
사실 TCP/IP를 이렇게 깊게 공부하게 된 데에는 나름의 사연이 있었다. HTTP 통신은 으레 Stateless한 통신 방식이라 하고, TCP는 Stateful하다고 말을 하는데 HTTP 통신이 TCP 프로토콜을 기반한다고 설명이 되어있어 너무 헷갈렸다.
단순히 OSI 7계층이니 TCP 3 Hand-shake같은 개념적인 내용만 보니 이해가 되지도 않고 머릿 속에 들어오지 않는 느낌..
그래서 이번 포스팅에서는 천천히 왜 패킷 전송 방식을 사용하게 되었으며, 각각의 계층에서 어떤 역할을 수행하고 이 역할에서 수행하는 바가 무엇인지 파악하여 결과적으로 HTTP와 TCP 차이를 다룰 예정이다.
우선 네트워크 통신 방식에 대해서 먼저 거슬러 올라가 보자.
회선 교환 방식(Circuit Switching)
패킷 통신이 등장하기 이전 과거 통신 방법은 '회선 교환' 방식이었다. 지난 인터넷 작동 원리에서 설명했듯 각각의 컴퓨터는 데이터를 전송할 때 라우터를 통해서 결과적으로 송수신하길 원하는 최종 컴퓨터(노드)에 도달하게 된다. 회선 교환 방식에서는 이러한 통신이 진행될 때 두 호스트만을 위한 이동 경로를 설정하고, 해당 경로를 통해서만 데이터를 주고 받게 한다.
아래 이미지를 예를 들어 호스트 B와 C가 통신하기 위해서는 설정된 경로인 '2-4-6' 을 이용하여 데이터를 송수신해야된다.

이러한 회선 교환 방식은 설정된 이동 경로가 할당이 해제될 때까지 다른 호스트들이 사용할 수 없게 되므로 효율성이 떨어지게 된다. 뿐만 아니라 지정된 회선 경로도 이동 효율과 트래픽을 전혀 고려하지 않아 데이터 전송 시 문제가 생길 가능성이 높아진다. 이렇게 단일 경로로 회선이 정해지다보니, 경로가 하나라도 끊기게 되면 다른 경로를 사용하기가 어렵다는 문제가 있다.
회선교환 통신의 문제점은 아래와 같이 정리할 수 있다.
- 단절에 취약하다. 회선 경로에 문제가 생겼을 때 다른 경로가 연결이 해제될때까지 기다려야 한다.
- 회선 경로가 트래픽을 고려하지않아 효율성이 떨어진다.
이러한 문제를 해결하기 위해서 패킷 통신이 등장하게 된다.
패킷 통신(packet Switching)
패킷 통신 방식은 회선 경로를 미리 설정하지 않고, 데이터를 잘게 쪼개어 패킷이라는 단위로 분리하여 라우터마다 최적의 경로를 선택하여 최종 목적지까지 이동하게 된다.
그렇다면 분리된 각각의 데이터가 자신의 목적지를 잃지 않고 여러 노드(라우터)를 거쳐서 최종 목적지까지 안전하게 도착하기 위해서는 출발지나 목적지와 같은 주소 정보가 데이터에 포함되어야 하지않을까?
아래 이미지와 같이 하나의 큰 데이터는 각 계층마다 통신에 필요한 주소지 정보를 담아 최종적으로 패킷이라는 단위로 데이터를 전송하게 된다. 그리고 이러한 절차를 아울러 '캡슐화'라고 한다.

그리고 도착 호스트에 도달하기까지 존재하는 라우터들은 패킷의 최종 목적지를 파악하여 라우터와 연결된 경로 중 가장 최적의 경로를 선택하여 패킷을 이동시켜준다.(이러한 로직을 라우팅이라고 부른다)
이러한 방식을 사용하게 되면 패킷 단위로 매 상황마다 최적의 경로를 탐색하여 이동할 수 있으므로 효율성이 증가하고, 각 라우터 간의 경로를 독점하지 않아 전송 효율이 높아지게 된다.
그중에서도 인터넷 프로토콜(IP)은 패킷 교환 네트워크에서 정보를 주고 받는 데에 사용하는 정보의 규약 중 하나다.
IP와 IP Packet
조금 전에 설명했듯 각각의 데이터가 오전송하는 일 없이 안전하게 송수신 되기 위해서는 데이터에 주소를 달아 보내야 한다. 인터넷 프로토콜(IP)는 아래 이미지와 같이 인터넷 상에서의 주소(IP Adress)를 데이터에 덧붙여 패킷이라고 불리는 하나의 블록 단위로 생성하여 출발지 IP에서 목적지 IP까지 패킷을 통해 전달하고자 하는 데이터를 전달하게 된다.

하지만 IP 프로토콜에는 한계가 있는데, 첫번째는 비연결성이다.
패킷이 받을 대상이 없거나, 서비스가 불가능한 상태여도 목적지 호스트의 상태를 파악할 방법이 없기 대문에 패킷을 그대로 전송할 수 밖에 없다.
두번째로는 비신뢰성이다.
패킷을 라우터를 통해 전송하던 중 장애가 생겨 중간에 소실이 되더라도, 데이터를 전송받는 호스트의 입장에서는 이를 파악할 수 없다. 뿐만 아니라 전달하려는 데이터의 용량이 클 경우 패킷 단위로 데이터를 전송하게 되는데, 각각의 패킷이 서로 다른 노드(라우터)로 전달될 수 있으므로 데이터를 전송하는 호스트의 의도에 맞지않는 순서로 목적지 호스트에 패킷이 도착할 수 있다.
이러한 단점을 극복하고자 TCP가 등장하게 되었다.
TCP/IP, 패킷통신규약의 보완
IP 프로토콜의 단점을 보완하기 위해 나온 TCP 프로토콜은 지난 IP 프로토콜에서의 단점이었던 비연결성과 비신뢰성을 보완한다. 위의 IP 프로토콜의 단점에서 설명했듯 가장 치명적인 문제는 바로 데이터가 소실되어도 목적지 노드에서는 이를 알 수 없다고 했다. 이러한 단점을 보완하고자 TCP/IP 프로토콜에서는 '순서'를 담은 정보를 패킷에 담아 함께 전송한다.
정리하자면 TCP 프로토콜은 신뢰성있고, 무결성을 보장하는 연결을 통해 데이터를 전송하는 프로토콜이고, IP 프로토콜은 패킷을 가장 효율적인 방법으로 목적지까지 전송하는 프로토콜이다.
그렇다면 데이터는 어떻게 캡슐화되고, 캡슐화된 패킷은 어떻게 인터넷으로 전송되는걸까?
TCP/IP는 규칙에 따라 4개의 계층으로 이루어져 있고, 해당 계층을 단계 별로 거치며 데이터가 캡슐화되는 과정을 거친다.
4계층 : 응용 계층(Application)
3계층 : 전송 계층(Transport)
2계층 : 인터넷 계층(Internet)
1계층 : 네트워크 인터페이스 계층(Network Interface)
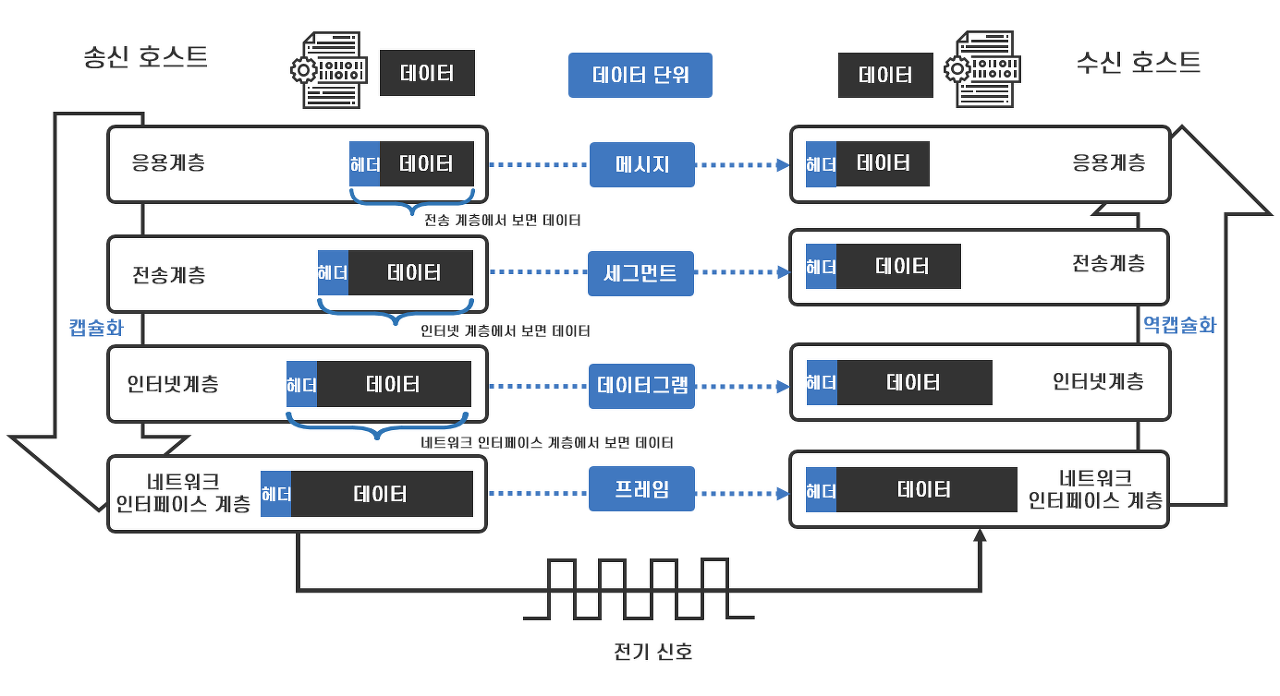
송신 호스트에서는 4계층에서부터 1계층에 이르기까지 절차를 거치며 데이터를 캡슐화하고, 수신 호스트에서는 패킷을 수신받아 1계층에서부터 4계층까지 차례로 패킷을 역캡슐화하는 과정을 거친다. 이러한 큰 흐름을 도식화하면 아래와 같다.

보다 구체적으로 TCP/IP 프로토콜에서의 캡슐화를 이미지를 통해 확인해보자.
각 계층은 헤더와 데이터 단위로 정의되고, 헤더는 각 계층에서 특정 프로토콜이 필요로 하는 정보에 대한 정보가 포함된다. 송신 호스트가 헤더를 추가하여 송신하면 수신 호스트는 각각의 계층마다 헤더를 참조하여 데이터를 처리하여 양 쪽 호스트에게 균일한 프로토콜을 사용할 수 있게 된다.

이를 조금 더 구체적으로 살펴보면 다음과 같다.

응용 계층에서는 애플리케이션이 사용하는 프로토콜이 필요로 하는 정보를 헤더로 정한다. 만약 HTTP 통신을 사용하는 애플리케이션이라면 응용계층에서 HTTP 헤더가 사용되게 된다.
이더넷 헤더에는 MAC 주소, IP 헤더에는 IP 주소, TCP 헤더에는 포트번호가 사용되는 것처럼, 각각의 계층에서는 사용하는 프로토콜에 따라 헤더에 반드시 송수신지의 정보가 포함된다.
그렇다면 수신 호스트는 어떤 과정을 거쳐 패킷을 역캡슐화하게 될까?
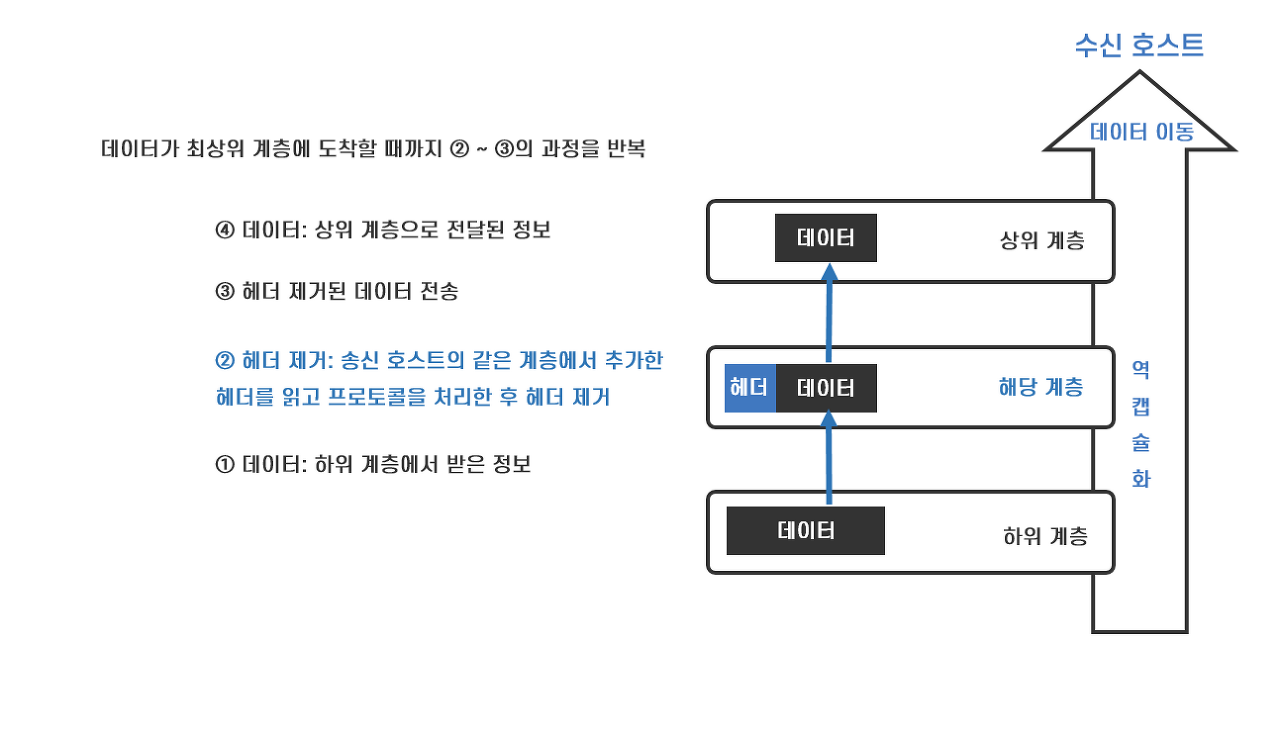
역으로 생각하면 쉽다! 송신 호스트를 통해 들어온 데이터는 각 계층을 거치며 헤더 정보를 사용해 해당 계층의 프로토콜을 처리하고, 헤더 부분을 제거하여 상위 계층으로 데이터를 전달한다. 결국 최상위 계층에는 송신 호스트가 보낸 데이터만이 남게 된다. 따라서, 캡슐화는 한 계층에서 추가된 헤더를 다른 계층에서 볼 수없게 하는 은닉 효과가 있다.
각 계층 마다 헤더에 추가되는 데이터를 응용 계층(4계층)에서는 메시지, 전송 계층(3계층)에서는 세그먼트, 인터넷 계층(2계층)에서는 데이터그램 또는 패킷, 네트워크 인터페이스 계층(1계층)에서는 프레임이라고 부른다.
통신 방식의 역사와 TCP/IP의 기초를 가볍게 살펴보았다.
'Computer Science > CS' 카테고리의 다른 글
| 넷플릭스로 보는 데이터 베이스 (2) | 2020.05.14 |
|---|---|
| 캡슐화(Encapsulation)이란 (0) | 2020.03.30 |
| information hiding, modularity에 대하여 (0) | 2020.03.22 |
| linear/binary classfication 와 sigmoid함수 정의 (0) | 2020.03.21 |
| 파이썬으로 쉽게 이미지 크롤링 및 파일 저장 (0) | 2020.03.06 |