2020. 5. 14. 21:26ㆍComputer Science/CS
1. 넷플릭스의 문제점
전세계에 1억 4000만의 유료 회원을 보유한 영상 스트리밍 플랫폼 ‘넷플릭스’. 화려한 타이틀을 갖게 되기까지 넷플릭스는 수많은 착오와 어려움이 있었다. 그 중에서도 넷플릭스의 성장에 가장 큰 영향을 미친 기술적 사건이 있었다. 바로 데이터 센터에서 클라우드로의 전환이다. 넷플릭스가 고유의 데이터 센터(DC)를 사용하는 것이 아닌 클라우드를 사용하게 된 계기에는 다음과 같은 사건이 있었다.
때는 2008년, 넷플릭스는 단일의 DC를 운용하고 있었으나 SPOF로 인해 3일간 소비자에게 DVD배송이 지연되는 문제를 겪었다. 특히나 점점 더 많은 유저를 포용하게 되는 넷플릭스의 입장에서는 DC 유지를 위한 공간, 동력 그리고 데이터베이스를 유지하기 위한 쿨링 시스템 보완 등 모든 것이 한계에 부딪히기 시작했고 이런 문제점에 대한 대안을 생각하게 되었다.
특히나 DC의 관계형 데이터베이스와 같이 수직으로 확장된 SPOF에서 벗어나 클라우드에서 수평으로 확장 가능한 높은 신뢰성 있는 분산형 시스템으로 전환해야 한다는 것을 깨달았다.
2. 넷플릭스의 해결 방안
그 중에서 넷플릭스가 최종적으로 자아낸 대안은 바로 ‘outsourcing the majority of our capacity planning and scale out’이었다. 클라우드 시스템의 경우 다양한 지역의 인프라를 유연하게 활용이 가능했고 탄력성 덕분에 페타 바이트급 저장 용량을 몇 분 내에 추가할 수 있었기 때문에 DC가 아닌 클라우드, 그중 에서도 Amazon Web Services를 선택하게 되었다. 넷플릭스는 클라우드 환경에 맞춰 새로운 인프라를 구성하여 DC 환경에서 겪었던 문제점을 클라우드로 옮 기지 않기를 원했다.
그렇기 때문에 그들은
첫째, 분산된 모델을 쉽게 관리가 가능하고
둘째, AWS에서 사용이 가능하며
셋째, Availability와 Partition tolerance를 갖추고
넷째, 대량의 유저들을 쉽게 처리할 수 있는 데이터 베이스 시스템을 찾았다.
이에 따라 기존에 사용하던 오라클을 Simple DB로 변경한 후 S3와 Cassandra로 보완하였다. 기존의 넷플릭스는 RDBMS인 ORACLE을 사용했다. 그들은 다음과 같은 형태로 데이터를 normalization 함으로써 데이터를 저장하고 기록했다. 그들이 시스템 이전까지 수행했던 normalization은 다음과 같았다.
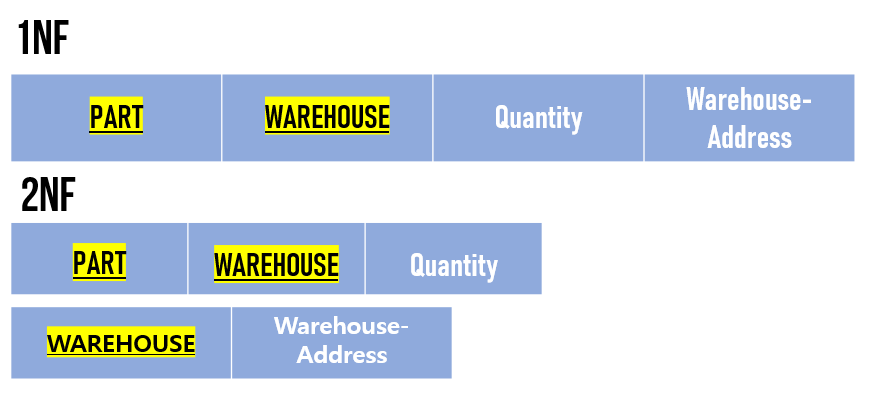
이러한 normalization은 다양한 문제점을 낳았는데, 필요한 데이터를 특정 파트에 Update할때 다른 파트의 동일 데이터가 변경되지 않아 update anomaly를 일으켰다.
심지어 특정 데이터를 위해 필요 이상의 데이터까지 지우는(deletion Anomaly)까지 발생하면서 비관계형으로의 전환이 필연적이었다. 그러나 비관계형 데이터베이스인 Simple DB로 변경하면서 denormalization을 적용하는 것이 쉽지 않았다.
특히, many-to-many나 many-to-one의 entity relationship일수록 이러한 현상이 더욱 심하게 나타났다.이에 따라 넷플릭스는 일부 relational한 데이터는 RDBMS에 남겨두면서 특정 데이터를 K-V store로 변경하는 과정을 진행하였다.
이러한 변환 과정에도 부족한 점이 몇 군데 있었는데,backup과 recovery를 할 수 없어 TEST DB와 Prod DB를 구분할 수 없다는 점과 native형태의 데이터를 지원하지 않는다는 것이었다. 뿐만 아니라 전역적이지 못해 global한 expansion을 가진 보완 시스템이 필요했다.
이러한 필요에 맞춰 등장한 것이 바로 ‘Cassandra’이다.
Cassandra는 2차원 모델로 효율적으로 데이터를 처리할 뿐 아니라 simple DB가 UTF-8 스트링으로 제한되어 있는 반면 Cassandra는 key의 native type과 sorting을 위한 type을 지원했다. 뿐만 아니라 Cassandra의 경우 Simple DB와 상이하게 데이터의 크기에 제한이 없었다. 더불어 빠른 read/write와 비정상적인 update/delete가 없다는 점에서 넷플릭스의 데이터 구조를 보충하기 매우 적절했다.
특히 Cassandra가 Backup과 Recovery를 가능하게 한 데 에는 ‘consistent Hashing’ 알고리즘이 빛을 발했다. 각각의 node(서버)가 일정 범위 안의 key값들을 소유함에 따라 일부 node가 죽더라도(혹은 node에 장애가 생기더라도) 다른 node가 생존하기 때문에 오류가 존재한 node의 key를 재분배하여 오류없이 서비스를 제공하는 것이 가능했다.
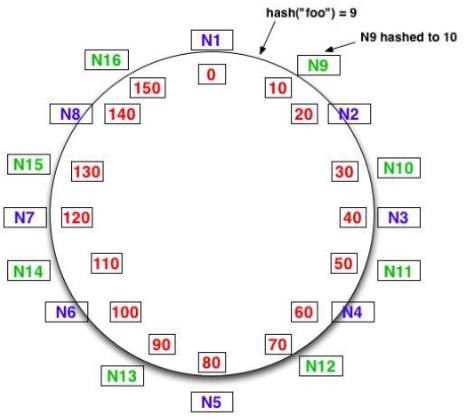
이러한 Cassandra의 가장 큰 이점은 바로 이러한 데이터의 분산이 전역적(Global Ring)으로 이뤄질 수 있다는 것이었다.(각각의 node가 각 region의 server 역할을 함으로써) 이러한 시스템 의 보완으로 넷플릭스는 미국에 한정된 서비스를 제공하는 것 이 아니라 다양한 해외 지역으로 넷플릭스 서비스를 제공하는 것이 용이하게 되었다.
3. Billing Department에서의 migration 예시
이러한 넷플릭스의 클라우드 이전(migration)에서 가장 큰 영 향을 받는 것은 바로 ‘Billing’ Part였다.
유저가 서비스를 결제 하는 데에 있어 혼선을 겪게 된다면 큰 문제를 발생시킬 것이기 때문에 migration을 신중히 해야할 뿐 아니라 전체적인 DB 환경을 재편성할 필요성을 느끼게 되었다.
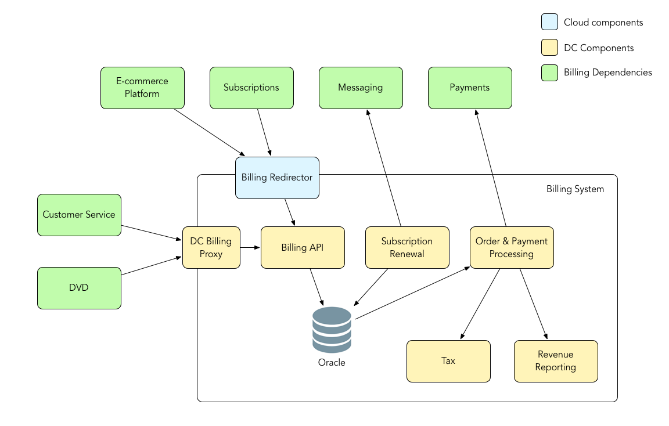
상단의 이미지는 넷플릭스의 migration이전의 DB 구조이다.기존에는 Billing 관련 고객 서비스, 유저 데이터까지 모두 Oracle을 통해 한 번에 처리를 했지만, 넷플릭스의 API가 multi-region과 높은 가용성을 요구했기 때문에 데이터를 여러 Data store로 흩어야만 했다.
이에 따라 유저 갱신과 고객 서비스 관련 Billing API를 Cassandra로 이동시키고, 결재에 관련된 전반적인 데이터를 MYSQL로 옮겨 cloud로 이전하는 과정이 진행되었다.
이러한 과정은 총 3단계로 분류되는데 그중 첫 단계는 ‘redirect new countries to the cloud and sync data to the data center’였다.
넷플릭스는 6개국을 새로 런칭함에 따라 부분적으로 6개국에 관련된 데이터를 cloud에 연결하고, DC의 데이터와 Cloud의 데이터를 연동하는 과정을 거쳤다. 다양한 지역을 포괄하기 위해선 Cassandra가 필요했고, 데이터의 정의를 위해 다음과 같이 각 entity간 relationship을 정의하는 과정을 거쳤다.
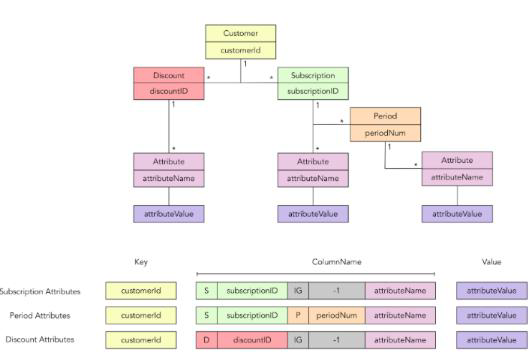
두번째 단계는 ‘Move all applications and migrate existing countries to the cloud’였다.
모든 application과 region을 Cloud로 이전하는 것을 의미하는 2단계에서는 결제 프로세싱과 tax service 등 결재 에 관한 전반적인 데이터를 모두 이전하였다. 위와 같은 과정을 거쳐 최종 단계에서 DC에 남은 것은 Oracle DB뿐이었다.
DC에 남아 있던 Oracle의 경우 Nosql(비정형 데이터베이스) 패러다임에 대한 좋은 모델이 아니었기 때문에 비정형 데이터(비디오, 이미지 등)가 압도적으로 많은 넷플릭스 측에서는 Cloud 환경으로 옮기기에 부적절하다 판단했다. 따라서, 비용이 적게 들 뿐만 아니라 Cloud에 적합한 AWS의 Aurora로의 이전을 지원해주는 MYSQL을 선택하게 되었다.
이에 따라 Oracle에서 MYSQL로 변경하여 최종적으로 Cloud에 올림으로써 DC에서 벗어나 온전히 Cloud에서의 서비스를 제공할 수 있게 되었다.
하단 이미지는 3단계의 과정을 거쳐 최종적으로 완성된 Billing department의 data architecture이다.
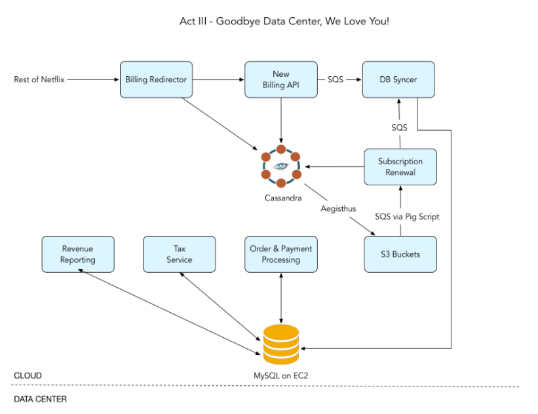
넷플릭스의 수많은 도전과 최신 데이터 기술을 통해 2008년 대비 스트리밍 서비스 이용 회원 수가 8배 증가 할 뿐 만 아니라 지난 8년간 월간 스트리밍 시간이 1000배가량 증가하는 등 유저의 서비스 이용도가 더욱 활발해질 수 있었다. 넷플릭스는 전세계에 분산된 AWS 클라우드 지역을 기반으로 글로벌 인프라를 유연히 활용할 수 있게 될 뿐만 아니라 유저들로 하여금 언제 어디서나 편안하고 즐겁게 콘텐츠를 스트리밍할 수 있도록 도왔다.
이러한 노력은 넷플릭스가 세계적인 인터넷 기반 서비스 기업으로 성장해나갈 수 있는 토대를 마련하도록 했다.
4. 끝맺으며.
간략히 설명해 쉽고 간단한 과정처럼 보엿겠지만, 클라우드로의 migration은 장장 8년간의 노력이 필요했다.위 서술에서는 simple DB와 Cassandra에 대한 설명으로 그쳤지만, 넷플릭스의 모든 프로세스를 이해하기 위해서는 Pig, Spark등 다양한 데이터 처리 프레임워크에 대한 이해가 필요했다. 표면 상으로 넷플릭스의 비결은 그저 ‘유저 친화적인’, ‘방대한 콘텐츠’라는 단순한 키워드로 대표되지만 이러한 키워드로 대표되기까지는 수많은 데이터에 대한 이해와 정의, 모델의 구현까지 엔지니어들의 철저한 설계가 없이는 절대적으로 불가능한 일이라는 것을 알 수 있었다.
대부분의 정보를 netflix tech blog에서 참고했다.
관심이 있다면 한번쯤 보는 것도 나쁘지 않은 것 같다.
https://netflixtechblog.com/netflix-billing-migration-to-aws-451fba085a4
'Computer Science > CS' 카테고리의 다른 글
| 문과도 한번에 이해하는 TCP/IP (0) | 2022.10.18 |
|---|---|
| 캡슐화(Encapsulation)이란 (0) | 2020.03.30 |
| information hiding, modularity에 대하여 (0) | 2020.03.22 |
| linear/binary classfication 와 sigmoid함수 정의 (0) | 2020.03.21 |
| 파이썬으로 쉽게 이미지 크롤링 및 파일 저장 (0) | 2020.03.06 |